



With its scalability and capacity to fuel machine learning (ML) algorithms, Snowflake, a cloud-based data warehouse, has transformed the industry. It is currently an essential component of many Fortune 500 businesses' ML pipelines.
In this post, we'll look at how to employ machine learning in a Snowflake data warehouse and what steps you need to take to get started. We'll also look at some of the advantages of employing machine learning in your organization.
What is Snowflake?
Snowflake is a well-known Cloud Data Warehouse that provides a wealth of functionality while remaining straightforward. It automatically scales up and down to deliver the optimal Performance-to-Cost ratio.
Snowflake is distinguished by the separation of Compute and Storage. This is crucial since practically every other Data Warehouse, including Amazon Redshift, mixes the two, indicating that you must decide the size for your most demanding task and then suffer the fees associated with it.
Snowflake also includes a variety of features and tools that make it easier to design and deploy data-driven applications.
Snowpark is a collection of interfaces enabling developers to utilize their preferred programming language.
Snowflake Connectors is a library of tools for connecting to popular BI products, open-source languages, data lakes, and data warehousing ecosystems, are among these features.
Snowflake's data cloud offers flexibility and scalability, allowing users to rapidly and easily increase computer capacity as needed. This enables enterprises to analyze enormous volumes of unstructured data in an effective manner, which can then be utilized to train machine learning models and other artificial intelligence solutions.
Key features of Snowflake
Snowflake differentiates itself as an integrated service platform from the rest of the cloud data warehouse options. So, let's take a quick look at those extraordinary characteristics.
1- Semi-structured data management
The architecture of the Snowflake data warehouse enables the storing of structured and semi-structured data in the same location by leveraging the VARIANT schema on read data type. VARIANT can hold both structured and semi-structured data.
Snowflake automatically parses the data, extracts the properties, and saves it in a columnar format as it is loaded. As a result, data extraction pipelines are no longer required.
2- Concurrent workload management
Concurrency is no longer a concern with Snowflake's multi-cluster design. It divides workloads to be run against its own computer clusters, which it refers to as a virtual warehouse. Queries from one virtual warehouse have no effect on those from another.
Having separate virtual warehouses for users and apps allows ETL/ELT processing, data analysis activities, and reporting to execute without competing for resources.
3- Cloud-independent platform
Snowflake is a cloud-independent solution. It is a managed data warehouse solution that is offered on all three cloud providers: AWS, Azure, and GCP, with identical end user experience on all three. Customers may simply integrate Snowflake into their existing cloud infrastructure and deploy it in areas that make sense for their company.
4- Intelligent automation
Snowflake's auto-resume and auto-suspend capabilities require very little management. When a query is initiated, it launches a computing cluster and suspends it after a certain amount of inactivity. These two elements provide optimal performance, cost control, and adaptability.
Setting up auto-scaling can assist-in automatically grow the number of clusters dependent on the volume of queries submitted to process concurrently in business situations where additional users are processing heterogeneous queries.
5- User-friendly administration
Acts as a data warehouse as a service (DWaaS), Snowflake allows businesses to set up and manage a system without the aid of DBAs or IT staff. Unlike on-premises platforms, there is no need for hardware commissioning or software installation patch-updates. Snowflake maintains software upgrades and adds new features and patches without causing disruption.
Snowflake also facilitates micro-partitioning automatically. This functionality lowers the need for manually indexing and clustering tables, even if these functions are provided in Snowflake.
Also Read: Data Warehouse Modernization: Understanding its concepts & implementation
Snowflake’s machine learning lifecycle
The first two steps are well supported by the Snowflake UI, SnowSQL, and the Snowflake Connector. Snowpark and UDFs contribute significantly to the last two phases. We'll go through how these tools may aid at each stage of the ML lifecycle in the sections that follow.
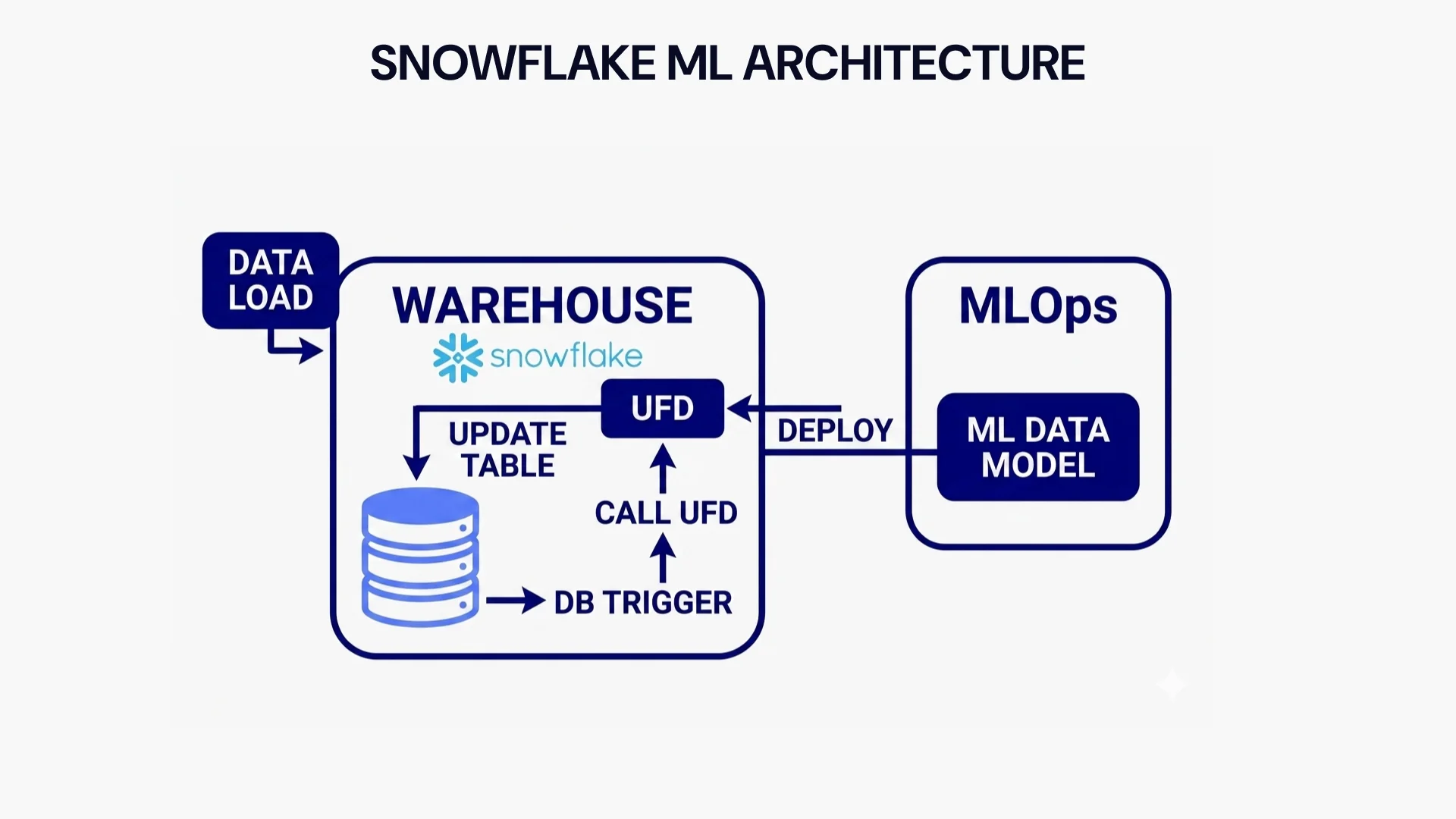
1- Data discovery & analysis
The finding of data is the initial step in constructing any ML model. Data Scientists must acquire or collect all accessible data relevant to the ML application at hand at this phase. When you already have all of your data in Snowflake, acquiring data becomes a piece of cake.
After gathering data, data scientists will do exploratory data analysis and data profiling to better understand the data's quality and usefulness.
2- Training data
Ad hoc analysis and feature engineering are a breeze using the Snowflake UI or SnowSQL. The Snowflake Connector for Python excels in data extraction and delivery to environments containing the most popular Python data science tools.
The nice thing is that Snowflake handles the heavy labor of transferring or converting this data. Reliable training and maintenance of ML models need a consistent training procedure, and lost data is a typical concern for repeatability.
3- Deploying data models
Snowflake support for ML model deployment has substantially enhanced with the introduction of Snowpark and Java user-defined functions (UDFs). UDFs are Java (or Scala) functions that receive Snowflake data and create a value using custom logic.
Another effective alternative is to deploy models learned in different languages using standard formats such as PMML. And, if pre- or post-processing is required to enable ML deployments, both UDFs and Snowpark are excellent data transformation tools.
4- Monitoring data
Writing ML predictions back to Snowflake simplifies the process of following up and closing the ML lifetime loop. Snowflake Scheduled Tasks may be an effective orchestration technique for tracking machine learning predictions. By scheduling actions that employ UDFs or constructing processes with Snowpark, you can even check for sophisticated concerns like data drift.
When problems are discovered, any analyst or data scientist may utilize the Snowflake UI to delve further and figure out what's going on. Dashboards based on machine learning predictions may also be generated utilizing the Snowflake connection or interfaces with popular business intelligence tools like Tableau.
How VLink can help?
Overall, employing Snowflake machine learning offers several advantages because of its scalability, query speed, integrated analytics platform, and cost-effectiveness. When implementing ML with Snowflake technology, firms should consider data preparation time as well as security concerns.
VLink can assist you with integrating data from several sources and loading it into destinations such as Snowflake to analyze real-time data using BI tools of your choosing. It will simplify data migration, making it dependable, easy to utilize, deploy, and secure.


Vice President, Strategy – VLink Inc.
Sambhavi Gopalakrishnan is the Vice President of Strategy at VLink Inc., bringing over a decade of experience in IT leadership, project implementation, and strategic growth. She possesses a strong foundation in technical project management and pre-sales, driving innovation and business transformation at VLink.

 Shivisha Patel
Shivisha Patel














